The PLOS Article-Level Metrics application is open source software that collects a variety of metrics about scholarly articles. The application talks to a number of APIs, and in return provides these metrics via an API. Work on this application therefore involves a lot of work on APIs, and some of the lessons I learned are summarized below, including changes we made in the latest ALM 2.8 release. Most of the things I mention are fairly obvious, but some of them could be starting points for a discussion. Good APIs are important for scholarly content, as we increasingly use computers to extract relevant information out of papers – see for example the cool projects done at the hack4ac event last month, including the one on PLOS author contributions that I participated in.
Eat your own dogfood
The first rule for building a good API is to use it yourself. The PLOS ALM API is used by the PLOS journal websites, ALM Reports, and the PLOS Search indexer, altogether more than 8 million API requests every month. Heavily using your own API makes sure that you quickly find and fix bugs, and that you build an API that is fun to use.

Doggie Donuts. Flickr Foto by Jamie.
I use the rplos and alm R packages to retrieve data from the PLOS Search and PLOS ALM APIs for most of my visualizations – the R statistical computing language is great for this purpose. Working with these APIs via an R client library can again provide valuable feedback not only for improving the ALM API, but also to make the rplos and alm packages better – and Scott Chamberlain from the rOpenSci project is very quick with updates.
Document your API
Documentation is important for all software, and that of course also includes APIs. The documentation for the Lagotto API is in Github. In the latest ALM release we have included the documentation right in the ALM application to make it easier to use, e.g. with the documentation for the PubMed API right next to the PubMed configuration tab. You also see the documentation when you sign up for an API key (see below).
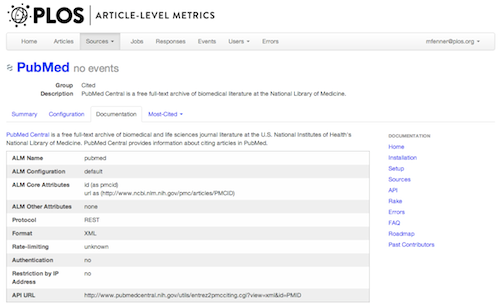
Make it simple to sign up for an API key
Most APIs require API keys, although some of them (e.g. Wikipedia) are fine with identification via the U*ser-Agent* header. API keys are not so much passwords to gain access to restricted information, but rather identifiers so that API providers know who is talking to them. For access to restricted resources we need something more secure e.g. authentication via OAuth or restriction by IP address.
In ALM 2.8 we made it much easier to register for an API key: simply sign in to alm.plos.org using your PLOS Journals account – the same account you use to receive customized email alerts for new articles, or to make article comments (we are using the CAS protocol for this).
For other organizations installing the ALM software we provide two other options: Mozilla Persona and Github OAuth. Persona doesn’t require any configuration and is very straightforward to use, Github OAuth is nice since many API users probably already have a Github account.
Version your API
No API is perfect and you will make changes over time. The only way to strike the right balance between a stable API that doesn’t break, and making changes that improve the API is to use API versioning, giving users time to transition to a new API. The ALM API is currently at version 3, and you indicate the API version in the URL:
http://alm.plos.org/api/v3/articles?api_key=123&ids=10.1371%2Fjournal.pmed.0020124
We will retire the old v2 APi that was launched in July 2012 on September 15.
REST is not REST
Most modern APIs are REST APIs. But there are many different ways how details can be implemented. I am mostly following the REST API Design Rulebook, and this also includes this rule:
File extensions should not be included in URIs.
The ALM API supports both JSON and XML responses, and the format has to be specified using the Content-Type header, defaulting to JSON. I’m considering adding a query string such as &format=xml to make it easier for web browsers to do content negotiation.
Another example is returning the 404 (**Not Found**) status code when a resource can’t be found. Mendeley is the only API that the ALM application is talking to itself that is also following this recommendation, the other APIs return a 200 (**OK**) status code even when they have no information about an article.
Something that almost never works in my experience is “automatic” REST APIs that automatically translate your database model. I very much prefer an intermediate layer between model and API (I use the Draper decorator and the RABL templating system) that lets me decide how I present the information in the API. Another reason is the versioning mentioned above: it is much easier to do versioning when the API code is not in the model, but in the presentation layer.
Make your API fast
Many factors go into the speed of an API, and I only want to mention three things:
- speed is important, in particular when looking at metrics for more than a handful articles
- caching is essential (we use extensive fragment caching)
- monitoring the performance of your API can help find bottlenecks
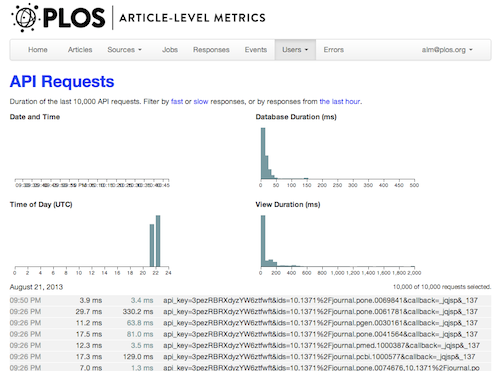
We collect the duration of all API requests and display the last 10,000 graphically using the d3.js and crossfilter Javascript libraries. You can see that a typical request takes 150-300 ms, whereas a cached request can be as quick as 10 ms. This tool was very helpful in fine-tuning the performance of the API during development.
Listen to feedback
This is an area where we could do much better. There is a PLOS API mailing list and a Github issue tracker, and we would love to get feedback in either of these places. Feedback is important, as we can’t possible anticipate all the uses of the API.
blog comments powered by Disqus