What is ten years old and has 1.2 billion interactions a day?
No, it’s not the Large Hadron Collider. Nor is it a philosophical riddle, but rather a commonly known fact in the tech world (news here). Facebook, the largest social network, is bigger than LinkedIn, Twitter, and Google+ – combined. At the same time, it is largely absent in the scholarly communications conversations, which focus on Twitter and Mendeley.
Facebook is seen by many as a social network for private and semi-private conversations while most public discussions around scholarly communication take place on Twitter. Certainly, we see Facebook activity for PLOS papers which have more mainstream appeal. But this circumstance does not reveal the bigger picture, and may yet veil the wider view:
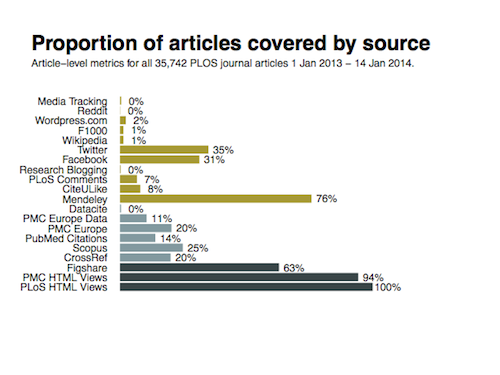
In fact, one out of every three of articles published last year was commented on, liked or shared in Facebook. That number is far greater than the number of the world’s tiny frogs, which would fit in the palm of a hand. For this reason, it has emerged as one of the most important Article-Level Metrics (ALM) data sources over the past couple of years. The combined number of Facebook comments, likes and shares is far higher than the number of tweets, about 750,000 vs. about 200,000 for all PLOS articles (not just 2013). And yet its presence has largely gone unnoticed.
{kind=link}
Due in part to its absence in the community’s conversations, much less is actually known about the nature of Facebook usage with scholarly research. For example, we see that Facebook activity seems to correlate with traffic to the PLOS website in our corpus, rather than to PubMed Central. (One caveat: we collect Facebook activity for URLs pointing to the PLOS website, but we do not capture the links to the article version that resides in PMC).
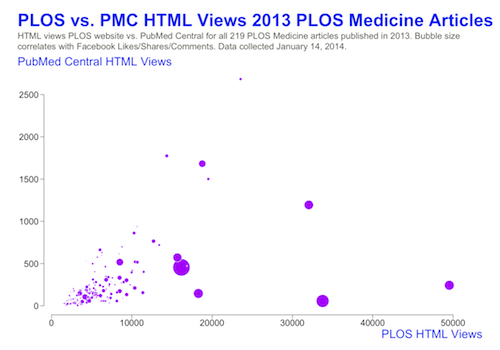
Out of these patterns, Facebook emerges as a valuable data source, especially with respect to the ongoing question of public versus scholarly interest in PLOS articles. The most popular PLOS articles on Facebook also reveal the kinds of content (and the paper titles) of interest to Facebook users.
Facebook is also under-appreciated amongst the data providers. From a technical perspective, the challenge is that its data quality relies heavily on the practices of publishers to make their content compatible with all other systems in the broader digital environment.
Facebook works great as a data source when it works. It has an open API that is fast, unrestricted by tough rate-limits frequently levied by others to ensure up-to-date data even in large corpuses, and comes equipped with good documentation and tool support for developers. Furthermore, Facebook nicely understands that all the different URLs pointing to an article – the DOI, the publisher journal page, any intermediary pages – are the same object, which means that the data provider only needs to provide a single DOI to the Facebook API to retrieve activity counts for all instantiations of the article in one fell swoop. For low volume calls this even works without API key:
As of January 2013, Facebook transitioned to using a canonical URL in their systems. PLOS encountered this change in Facebook’s methods when we noticed aberrant counts and investigated the elevated numbers. We have shared what we learned in the documentation found on the new ALM community website about how the ALM application collects Facebook metrics. Later in 2013 we found that while the requirement for the canonical URL is automatically satisfied by many websites, meta tags "link rel=canonical" and "property og:url" ensure that different URLs are recognized as pointing to the same page.
As Google and Facebook, along with an increasing number of web services, employ similar methods in collecting and organizing content pulled across the internet based on the canonical URL, we see a set of best practices emerging for producers of this content – publishers alike – to make sure that it is accessible not only to their human readers but machine consumers as well.
Facebook provides a nice Debugger Page to test URLs to confirm that their content complies. Every publisher (or anyone else) can input a DOI into the service, and then see what canonical URL Facebook will use and whether it generates any errors. Some of the problems we have seen include:
- pages that require human intervention (e.g. to accept a cookie or to click on one of two choices)
- journal pages that use link rel=canonical wrong, usually linking to a page from where users are redirected somewhere else
- indefinite redirect loops
- journal pages that are human-readable, but send back an “access not allowed” status
All these examples confuse Facebook robots (and likely Google ones as well) such that they cannot accurately collect metrics for a page. While we did not systematically investigate this across other websites, it is clear this is not a small problem given the aberrations encountered in our initial investigations. Luckily the fix is easy and probably in every publisher’s interest, as this not only improves the quality of the Facebook numbers, but probably affects how people can find the journal article using Google and other search engines, as well.
The only workaround for getting metrics from publishers where the canonical URL is broken is to use a different Facebook API. Facebook also provides an API to public wall posts that include a link to an article. The advantage of this API is that we don’t need to worry about canonical URLs and can get the text of the public wall post. and not just numbers for comments, likes and shares. The big disadvantage is that the numbers retrieved are only a small subset of the total Facebook activity around an article.
We believe that canonical URLs have become standard practice not just for users of Google and Facebook, but have evolved as a best practice that is also relevant to scholarly publishers and article-level metrics.
blog comments powered by Disqus