As part of the ALM workshop described in more detail in the previous post we also met for an ALM Data Challenge which took place in the PLOS offices on October 12.
Many readers are probably familiar with a hackathon, where a group of people collaborate on one or more software projects for a day (or a few days). This is what we did at the ALM workshop last year, but this year we wanted to focus on the data, and the interesting things we could do with them, rather than the software development aspect. We thought that this makes it easier for people who are not software developers to get involved, to get something done in the limited time available, and to have something that can be continued after the workshop.
The following article-level metrics/altmetrics datasets were made available for workshop participants:
- Altmetric: newspaper and magazine tracking data (news story URLs & DOI pairs) that have been marked up with additional information like country of origin, whether it’s a print / online only source etc. There’s lots of interesting possibilities around checking to see if German science is reported more by German outlets, seeing how much different countries rely on press releases etc.
- ImpactStory: 19 reference sets that include metric counts and percentiles for each of 100 randomly-selected products. 10 of the reference sets are of articles, 4 of github repos, 5 of dryad repositories. Each reference set 100 random products selected from a given publication year, so the last 10 years of articles (randomly drawn from Web of Science), last 4 years of github, etc.
- Mendeley: 140k rows from the Mendeley database that contain basic bibliographic data + mendeley stats + keywords, categories, tags + identifiers for a random selection of papers in biomedical science added to our database from 2010-2012. Readership values are from 0 to 365, average 5.7.
- PLOS: historical usage data (page views and article downloads per month) for all PLOS articles published since 2003, separate for the PLOS website (link to data on figshare) and PubMed Central (link to data on figshare).
- CrossRef: June 2013 log files for the dx.doi.org DOI resolver.
- CrossRef(collected by me via the CrossRef RanDOIm service): a random set of 5,000 DOIs each for 2011 (link to data on figshare) and 2012 (link to data on figshare).
We were about 20 people, and after describing the datasets that were made available, everyone introduced himself and what kind of data analysis he or she would be interested in. We then formed groups that worked on the following projects for the rest of the day:
- Science that didn’t make the news: analysis of highly bookmarked articles in Mendeley that are not mentioned in the news or in science blogs using Altmetric data. Eva Amsen described the project in detail in a blog post.
- DOI resolver logs and social media activity: It took some time to load 2.4 Gb of data into a database, but then the group could correlate social media activity with referrer log entries on a timeline. One result was that only a portion of log entries actually had a referrer URL, and that a good chunk of these referrals came from the English Wikipedia.
- Data standardisation: Compare ALM/altmetrics data from different service providers for the same set of articles
This list is unfortunately incomplete as I was too busy to take notes about the other projects.
I worked in the last group and will describe this project in more detail. Scott Chamberlain published a paper in July where he compared the metrics from ImpactStory, Altmetrics, Plum Analytics for the same set of PLOS articles and found that overall the numbers were different enough to be worried (see also Scott’s blog post and our blog post from from August). Comparable metrics from different service providers is obviously a big step towards standards and best practices for altmetrics.
We wanted to repeat this analysis with a larger set of data, and after a short discussion in our group (Zoreh Zahedi, Juan Alperin, Scott Chamberlain, Martin Fenner) decided that 5,000 articles each for 2011 and 2012 would be good. Older articles have more citation data available, but often not as many altmetrics data points. We used two CrossRef APIs to get the set of random DOIs (limited to journal article content type) and the article titles. Because only the publication year is a required field, we set the date to January 1st for each DOI (one of the limitations of the datasets).
In a second step these 10,000 DOIs were loaded into an instance of the PLOS Open Source ALM application set up on Amazon AWS and started collecting metrics. You can visit the ALM application with these 10,000 DOIs at http://almhack.crowdometer.org. Some preliminary results can be seen in the screenshot from the ALM admin dashboard:
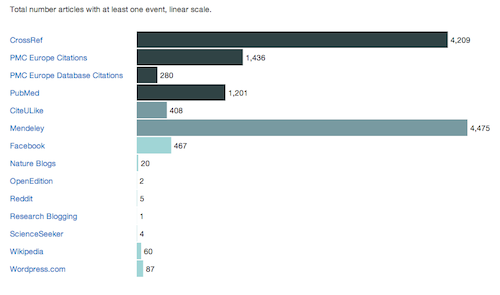
More than 40% of the articles have been cited at least once or have been bookmarked on Mendeley, whereas the numbers for Facebook, Wikipedia and science blogs were much smaller. We also discovered some technical issues, e.g. documents labeled as “journal article” that were clearly something else (e.g. 16 table of contents pages, obviously with very different metrics), and problems with getting the journal page URL from a DOI (this affected the Facebook numbers).
Scott Chamberlain pulled some preliminary metrics data out of the application using the API of the ALM application and the alm rOpenSci library for R, and Euan Adie ran the set of DOIs against his Altmetric database. As is typical for a hackday, we couldn’t finish all that we wanted to accomplish, but both the set of random DOIs and the ALM data are available for everyone to play with.
The three things I want to do next is a) get the publication dates as exactly as possible (as you can’t really compare metrics from a January 2012 article with a December 2012 article), b) resolve the technical issues (e.g. by excluding DOIs for content that is not a journal article) and c) compare the metrics against metrics collected by Altmetric, ImpactStory and Plum Analytics. Please contact me if you want to help with this effort and/or want admin access to the ALM application.
This was the first data challenge that I participated in. Although it was similar to a typical hackday in many ways, I liked the focus on data and on interesting questions regarding these data. Certainly a format worth repeating.
blog comments powered by Disqus